Running LLMs Locally with Docker Model Runner
A comprehensive guide to running large language models locally using Docker's new Model Runner feature, including setup, API integration, and building a chat application.

Running large language models (LLMs) locally has become increasingly popular for developers who want privacy, cost control, and offline capabilities. Docker's new Model Runner feature makes this process incredibly simple by providing a unified way to run AI models with just a few commands. In this guide, I'll show you how to set up and run LLMs locally using Docker's Model Runner.
Why Run LLMs Locally?
- 🔒 Privacy - Your data never leaves your machine
- 💰 Cost Control - No per-token API costs
- 🌐 Offline Access - Works without internet connection
- ⚡ Performance - No network latency
- 🛠️ Customization - Full control over model parameters
What is Docker Model Runner?
Docker Model Runner (DMR) is a new feature that allows you to run AI models directly through Docker with a simple command-line interface. It provides:
- Easy Model Management - Pull and run models with simple commands
- OpenAI-Compatible API - Standard REST endpoints for integration
- GPU Support - Automatic GPU acceleration when available
- Model Registry - Access to pre-built models from Docker Hub
Prerequisites
- Docker Desktop (latest version)
- At least 8GB RAM (16GB+ recommended)
- Optional: NVIDIA GPU for better performance
Getting Started
Step 1: Download a Model
Docker Model Runner provides access to various pre-built models. Let's start with Google's Gemma 3 model:
docker model pull ai/gemma3This command downloads the ai/gemma3 model from Docker Hub. You can browse other available models at the Docker Hub Model Registry.
Step 2: Run the Model
Once downloaded, you can run the model with a single command:
docker model run ai/gemma3That's it! You now have a running LLM locally. The model will start and be available through Docker's Model Runner API.
Building a Chat Application
Now that you have a running LLM, let's build a practical chat application to demonstrate its capabilities.
Step 3: Enable Host-Side TCP Support
To access the model from your host machine, you need to enable TCP support in Docker Desktop:
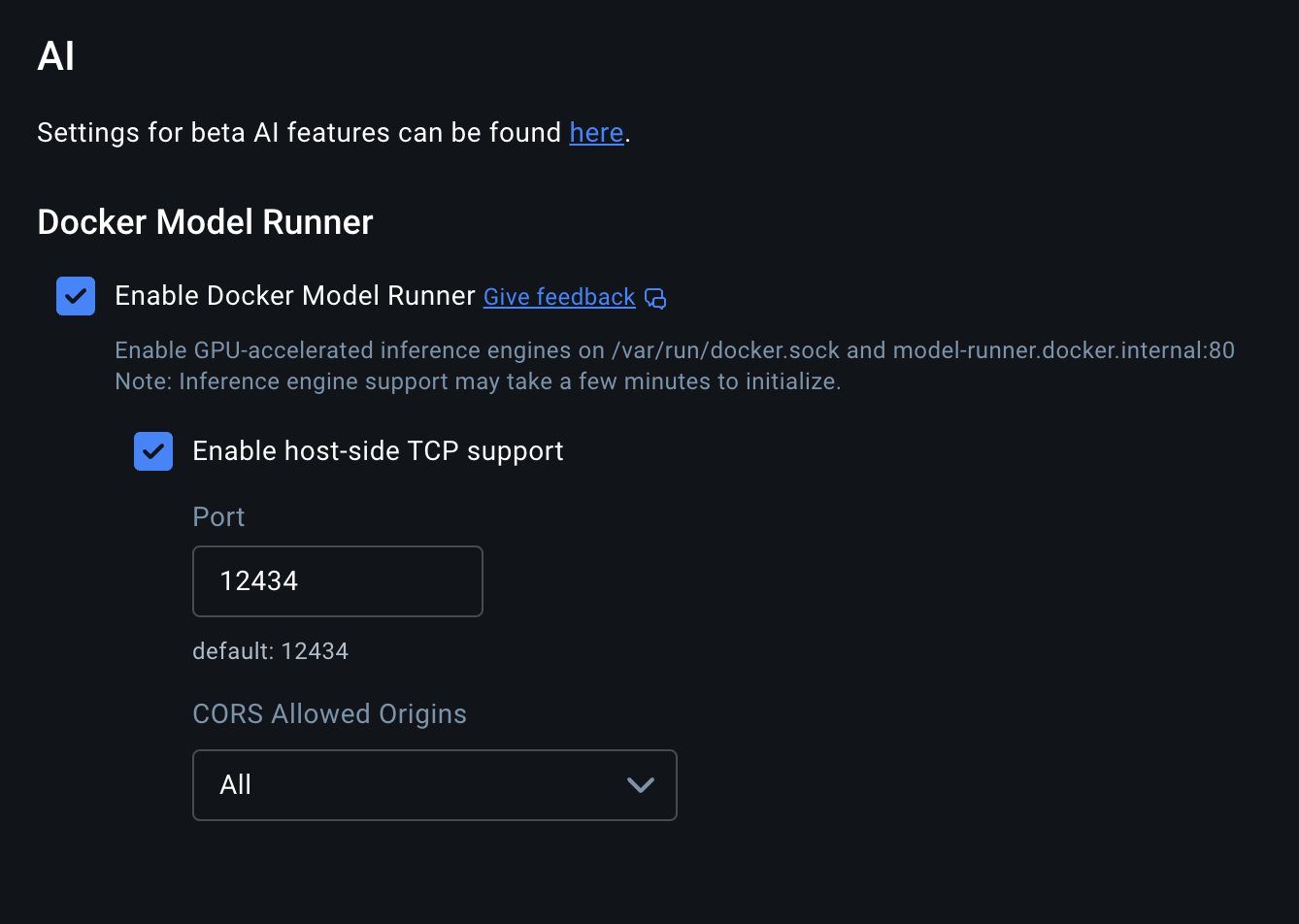
- Open Docker Desktop
- Go to Settings → AI
- Enable "Host-side TCP support"
- Set the port (default: 12434)
Step 4: Clone the Example Application
I've created a complete Node.js chat application that demonstrates how to integrate with Docker Model Runner:
git clone https://github.com/sourabhs701/node_docker_genai.git
cd node_docker_genaiStep 5: Install Dependencies
pnpm installStep 6: Start the Application
pnpm devThe application will start on http://localhost:3000 and connect to your running Gemma 3 model.
API Integration
Docker Model Runner provides OpenAI-compatible endpoints, making it easy to integrate with existing applications. Here's how to use the API:
Available Endpoints
The Model Runner exposes several endpoints as documented in the DMR REST API Reference:
- Chat Completions:
POST /engines/llama.cpp/v1/chat/completions - Text Completions:
POST /engines/llama.cpp/v1/completions - Embeddings:
POST /engines/llama.cpp/v1/embeddings - Model Management:
GET /models,POST /models/create
Example API Usage
// Using fetch to call the chat completions endpoint
const response = await fetch(
"http://localhost:12434/engines/llama.cpp/v1/chat/completions",
{
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({
model: "ai/gemma3",
messages: [
{
role: "user",
content: "Explain Docker in simple terms",
},
],
max_tokens: 150,
temperature: 0.7,
}),
}
);
const data = await response.json();
console.log(data.choices[0].message.content);Available Models
Docker Hub hosts a growing collection of pre-built models. Some popular options include:
- ai/gemma3 - Google's latest Gemma model
- ai/llama2 - Meta's Llama 2 model
- ai/mistral - Mistral AI's model
- ai/codellama - Code-specialized Llama model
Browse all available models at the Docker Hub Model Registry.
Advanced Usage
Custom Model Configuration
You can customize model behavior by passing parameters:
docker model run ai/gemma3 --temperature=0.8 --max-tokens=200Multiple Models
Run multiple models simultaneously on different ports:
# Terminal 1
docker model run ai/gemma3 --port=12434
# Terminal 2
docker model run ai/llama2 --port=12435Conclusion
Docker Model Runner makes running LLMs locally incredibly simple and accessible. With just a few commands, you can have a fully functional AI model running on your machine with a standard API interface.
The combination of Docker's containerization benefits with easy model management creates a powerful platform for local AI development. Whether you're building chatbots, content generators, or experimenting with AI, Docker Model Runner provides the foundation you need.
Resources
- Docker Model Runner API Reference
- Docker Hub Model Registry
- Gemma 3 Model on Docker Hub
- Example Chat Application
Happy coding and AI experimenting! 🚀